This is a major new release of the search engine software, corresponding to nearly four months of changes. In these months, the state of the code hasn’t been stable enough for a new release, but it’s now been brought to a stable point.
Release Highlights:
- The installation procedure has been cleaned up.
- It’s now possible to run the search engine in a white label/bare-bones mode, without any of the Marginalia Search branding or logic.
- The Marginalia Search web interface has been overhauled. The site-info page has especially been given a large upgrade.
- The search engine can use anchor texts to supplement keywords.
- The search engine can use multiple index shards.
- The operations GUI has been overhauled.
- An operations manual has been written.
- The crawler can now resume crawls in process due to intermediate WARCs.
- The search engine can import several formats without external pre-processing.
- The Academia filter has been improved
- The Recipe filter has been improved
- The system now penalizes documents that have obvious hallmarks of being written by ChatGPT in its quality assessment.
Other technical changes:
- Several bugfixes in the ranking algorithm has improved search result precision
- Domain link graph have moved out of the database, improving processing time
- The system can be configured to automatically perform db migrations
- Ranking algorithm improvements
Known Limitations:
- Service discovery is currently a bit limited, making it only possible to run the system within docker (or similar) at this point, as host names and ports are not configurable. This is not intended to be a permanent state of affairs.
- The Marginalia Search website has lost its dark mode.
- There might be an off-heap resource leak in the crawler. It’s primarily a problem with very long crawl runs.
Barebones Install
The system can be configured to run in a barebones mode, which only starts the minimal number of services necessary to serve search queries. A HTTP/JSON interface is provided to enable the search engine to act as a search backend.
There isn’t really any good “off the shelf” ways of running your own internet search engine. Marginalia Barebones wants to address that. Out of the box it offers both a traditional crawling-based workflow, as well as sideloading worflows for various formats, such as WARC or just directory trees, if you’d rather crawl with wget.
As this is this is a first time it’s been possible to run the search engine in this fashion, it’s at this stage not very configurable, and a lot of the opinionated takes of the Marginalia search engine are hard coded in. These are intended to be relaxed and made more configurable in upcoming releases.
The barebones install mode is made possible in part due to an overhauled installation procedure. A new install script has been written offering a basic install wizard. Configuration has also been broken out into mostly being a single properties file.
A video demoing the install and basic operations of this is available here:
Overhauled Web Interface
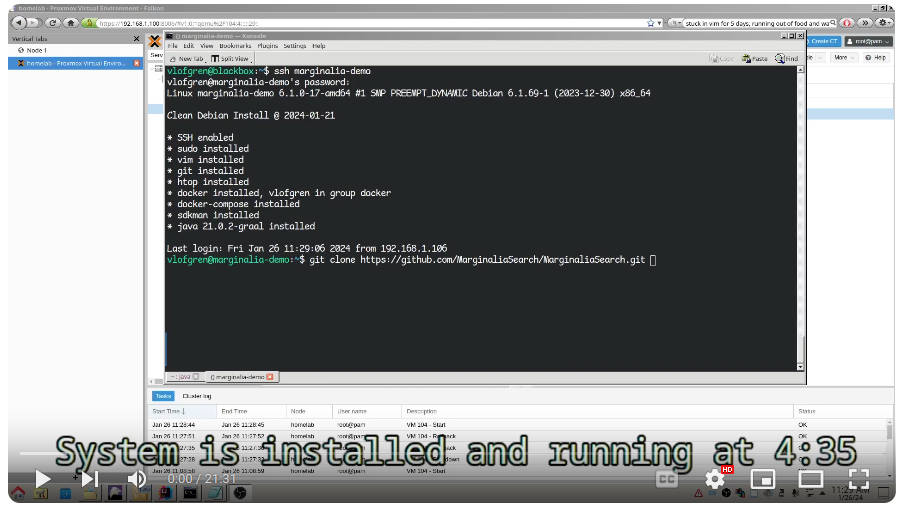
The Marginalia Search web interface has been overhauled. The old card-based design didn’t really work out, and has been replaced with something a bit more traditional. The filters have moved out of a dropdown next to the search query and into a sidebar, making them more visible.
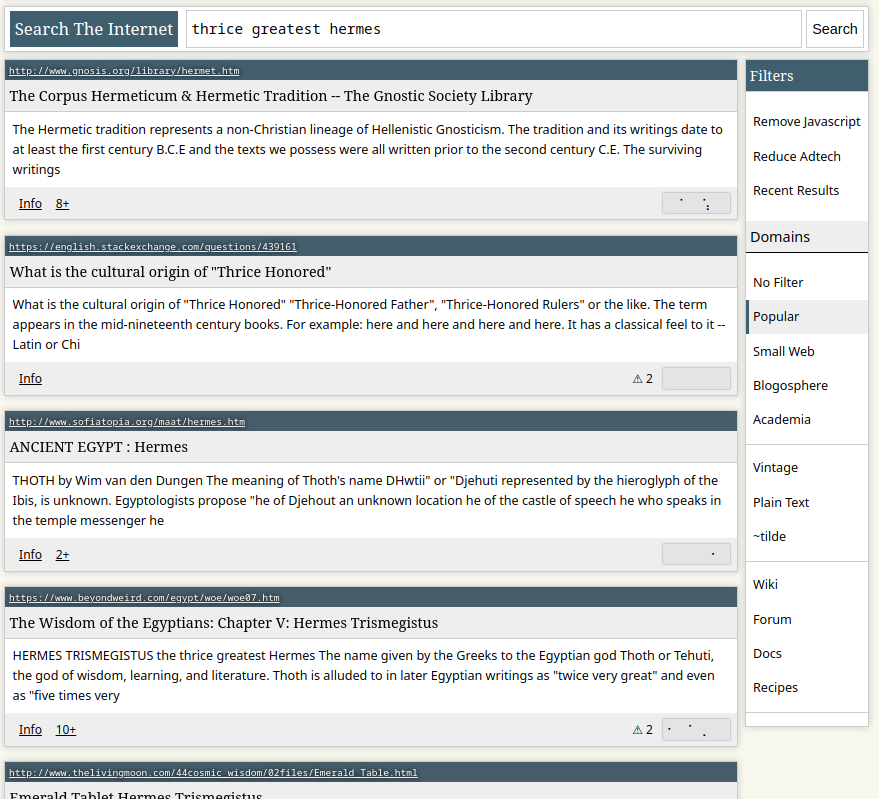
The site info view has been significantly overhauled, integrating several discovery/exploration features. Experimental RSS support is added, as well as
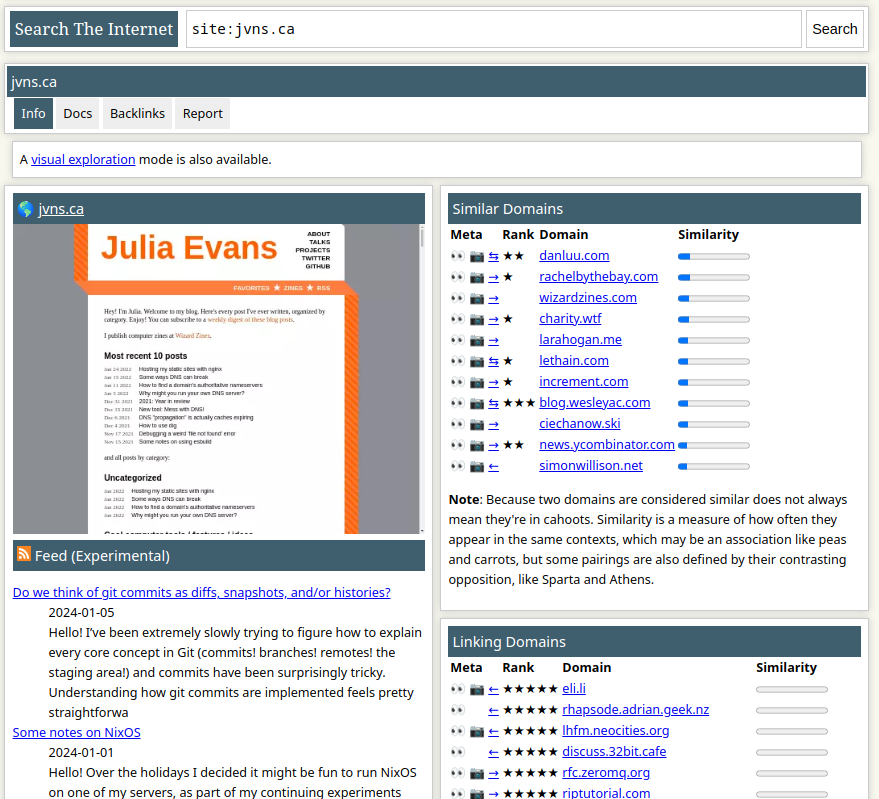
The site info view also presents information about the site’s IP and ASN, both of which are searchable. You can also include (or exclude) autonomous systems by name in the search query, e.g. as:amazon.
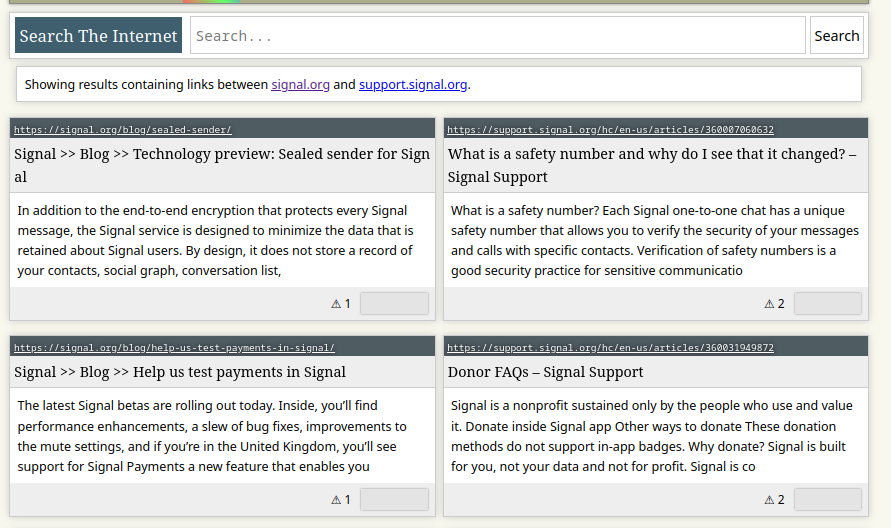
Anchor Text Support
The search engine can now use anchor texts to supplement the keywords in a document. This has had a very large positive impact on the search result quality! An in-depth write-up is available going over the details of this change.
Marginalia Search makes its anchor text data freely available, along with the other data exports.
Multiple index shard support
The system now has support for multiple backing indices. This permits a basic distributed set-up, but can also e.g. allow pinning different parts of the index to specific physical disks. There is a write-up going over the details of this change.
Some of the internal APIs have also been migrated off REST to GRPC. This is an ongoing process, and several more APIs are slated for migration in future releases.
New Operations GUI
This concludes the final polishing pass on the operations GUI. The GUI offers control over all of the operations of the search engine, as well as monitoring and configuration.
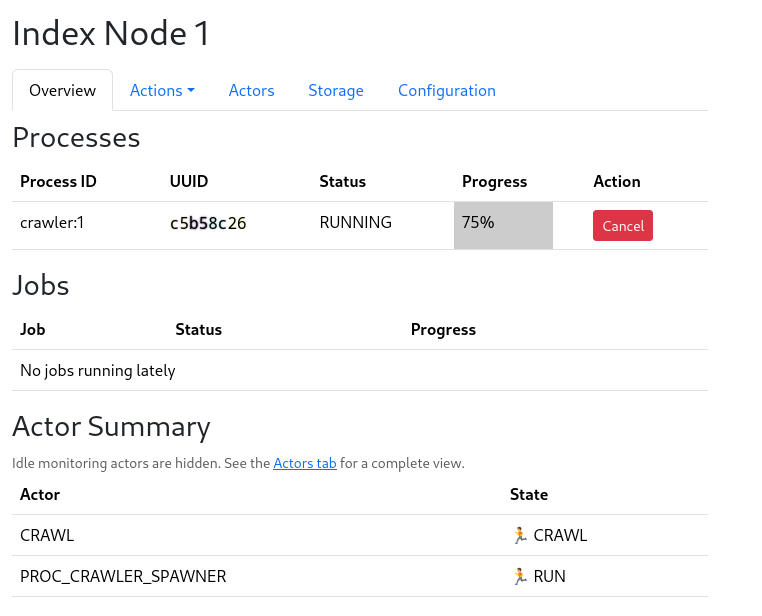
Most operations are now available via user-friendly guides with inline documentation.
A manual is also available at https://docs.marginalia.nu/, explaining the concepts in depth.
Commits
Crawler Modifications
The crawler can now resume crawls in process due to storing in-progress crawls in the WARC format. Upon completion of a domain, the WARC is converted to parquet. The system can be configured to keep the WARCs for archival purposes, but this is not the default behavior as WARC files are very large, even when compressed.
Previously the crawler would restart crawling a domain from scratch if it crashed or was restarted somehow. Thanks to this change, this is no longer the case.
The crawl data is no longer stored in compresed JSON, as before, but in parquet. This change is still not 100% complete. This is due to the needs of data migration. To avoid data loss, it needs to be done in in multiple phases.
In implementing this, a few inefficiencies in dealing with very large crawl data was discovered in the subsequent processing steps. A special processing mode was implemented for dealing with extremely large domains. This runs with a simplified processing logic, but is also largely not bounded by RAM at all.
Improved Sideloading Support
The previously available sideloading support for stackexchange and wikipedia-data has been polished, and no longer need 3rd party tools to pre-process the data. It’s all done automatically, and is available from an easy guide in the control GUI.
The index nodes have been given upload-directories, to make it easier to figure out where to put the sideload data. The contents of these directories are visible from the control GUI.
(also a few others)
New Search Keywords:
as:ASN– search result must have an IP belonging to ASNas:asn-name– search result must have an AS with an org information containing the stringip:country– search result must be geolocated in countryspecial:academia– includes only results with a tld like .edu, .ac.uk, .ac.jp, etc.count>10– keyword must match at least 10 results on domain (this will likely be removed later)