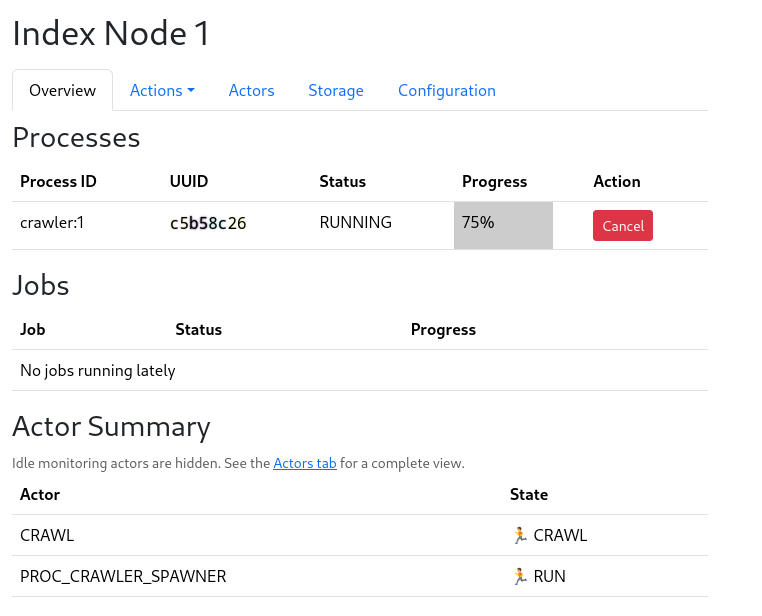
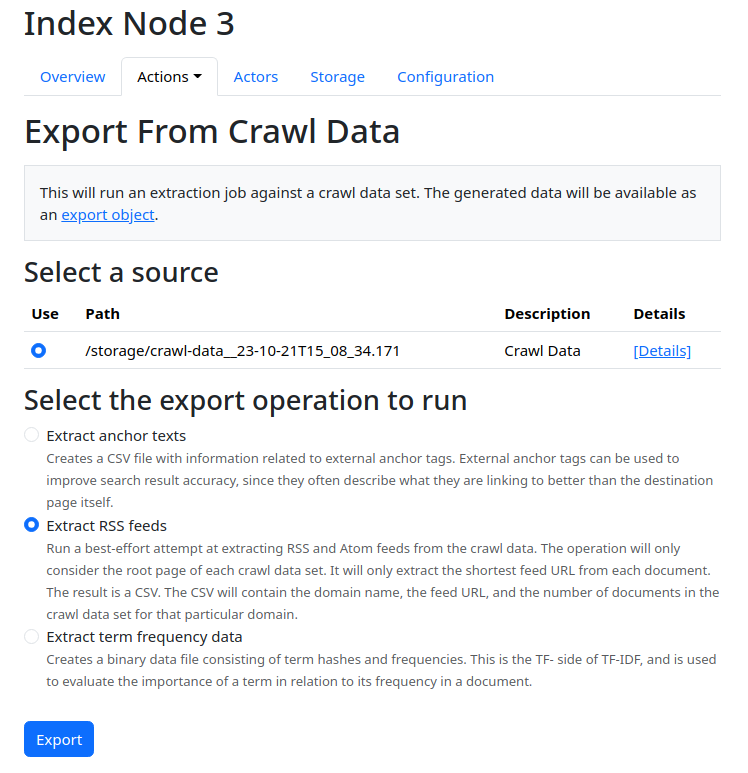
This is a new major release of marginalia search, mostly leaning toward the technical side.
Emphasis has been on ensuring the search engine has the technical capabilities to serve more types of queries, especially longer queries which it previously did not handle very well.
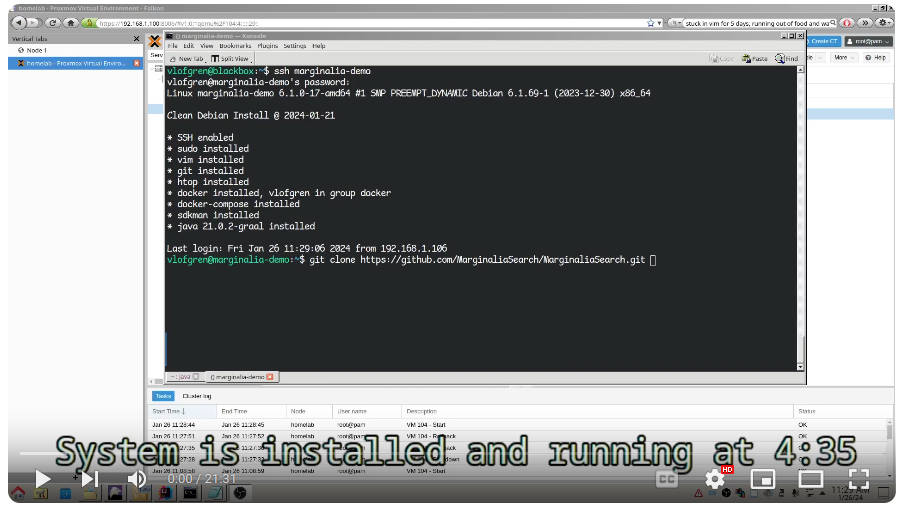
Effort has also been put toward making sure it’s possible to install and run outside of docker. There is still some work to be done to streamline the installation process, but we’re getting there.
Search Improvements
Query Parsing
The query parsing and evaluation model has been re-written from scratch, as the original model was very flaky and hard to maintain. The new model performs query segmentation, and introduces a graph based model for bag-of-words query evaluation. Writeup, PR#89
Position Index and Phrase Matching
Full phrase matching has been implemented, allowing not just “quoted search terms” to function better, but the result ranking to consider the word order in the query. This required the introduction of high accuracy keyword position data, and a re-write of the index. Writeup, PR#99
The constraints on valid keywords have also been relaxed, meaning it should be easier to search for e.g. program code, accepting tokens such as “$var” or “strlen()”.
Slop
As part of this change, ephemeral data is now stored in the built-for-marginalia Slop format, with a new marginalia adjacent library for reading and writing this data. As a result of this, and optimizations surrounding it, index construction is time is now reduced by something like 80% in production.
Since this is a bespoke format, portability is ensured via the format being self-documenting and simple to a fault, with the explicit design goal that anyone should be able to parse it by just looking at the file names, which may look like e.g.
cities.0.dat.s8[].gz
cities.0.dat-len.varint.bin
population.0.dat.s32le.bin
average-age.0.dat.f64le.gz
‘search.marginalia.nu’ Application
Capture Function
A new screenshot capture function has been added, screenshots are fetched/refreshed by page views on the site:-viewer, whether by human browsing or GoogleBot’s rambling. Request throttling and re-fetch timers are in place to ensure this can’t be used for abuse. This ensures that frequently viewed sites are kept up to date, and has helped the screenshot library grow quite considerably. PR#120
Pagination
Pagination has been added for the search results. This is in a sense fake pagination, made possible because each index node fetches the total number of requested results, but only the best results across all nodes are selected in the query service, and the pagination is done within this set. It’s unlikely paging beyond page 8 or 9 is going to be helpful anyway. PR#119
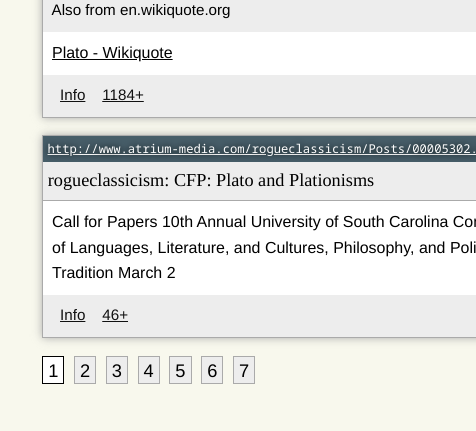
Base application
Added a new domain management view that permits inspection and index node assignment on a domain level, as well as the easy addition of new domains to be crawled.
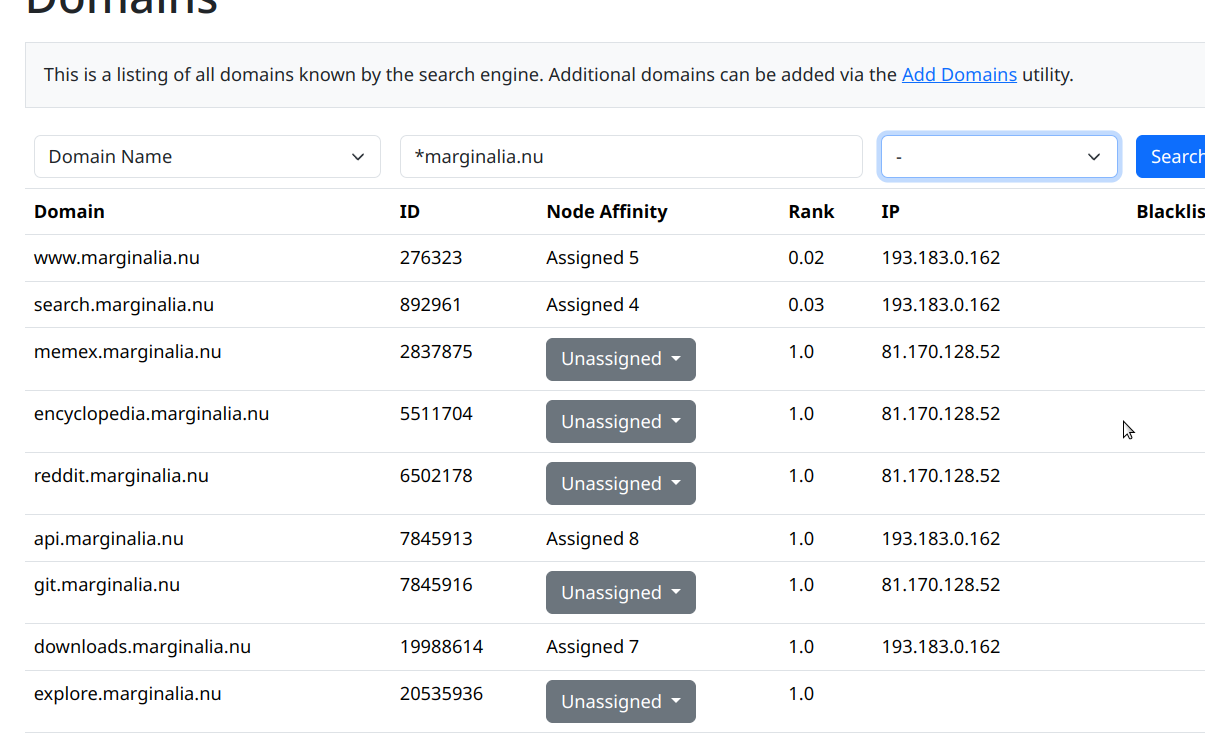
Because we can now manage the domains table directly, the crawl spec abstraction has been retired. This was historically used to specify which domains to be crawled, but was clunky and difficult to interact with.
Architecture
The project has been migrated to JDK 22.
A new dependence on zookeeper has been introduced, to let the project self-manage routing and port mapping via a new service discovery registry. Zookeeper is a key value store that is well suited to distributed state management and configuration keeping.
This is to liberate the project from being dependent on docker, and as a result the system can now, again, run on a bare metal Linux installation, without having to go through the rigmarole of manually mapping each service to a port and IP-address.
A side effect is that the code can be configured to run in any number of configurations. Users with only one machine may not want a bunch of small services, so they can in theory assemble the entire application as one service instead.
As part of this, the old client-service library was overhauled, and a lot of questionable technical choices were expunged. The services now all talk gRPC instead of HTTP.
Misc
Findings from UX and Security assessments have been addressed. These were mostly small things PR#93 PR#101
Error recovery and logging has been improved for the “download sample crawl data” actor, as it was previously a bit opaque with what it was actually doing.
The CSS was given a bit of an overhaul and dark mode was revived, work by @samstorment PR#94 PR#98
A new actor has been added that periodically polls certain links for outbound links (e.g. hacker news), and adds them to the list of domains to be crawled, to help automatically discover interesting links.
Work In Progress
The Crawler now attempts to fetch favicons. The aim is to be able to present them along with the search results in the future, but for now we’re just gathering them.
Content-type probing via HEAD requests is disabled for now, evaluating the use of Accept header instead. The crawler would previously attempt to, depending on how much the path looked like it might be some file format we’re not interested in, probe URL endpoints with a HEAD first and fetch the content-type. It’s questionable whether this was ever a good idea.
Notable Bugfixes
- Fixed bug that caused some domains to fail to fully crawl. The exact circumstances are a bit flaky, but in some cases, the crawler would halt at the first document, and fail to load links from it.
- The crawler was not properly stripping the W/-prefix from weak E-tags, when making conditional requests, causing unnecessary traffic. This has been corrected.
- Fixed bug where the summarizer would pick up the contents of <noscript> tags. This caused escaped HTML to sometimes show up in the document summaries, most commonly goat counter’s code.
Bugs found in dependencies
- Identified the cause of transient instabilities during index construction as being caused by a JVM compiler error. This should be corrected in the latest version of GraalVM JDK 22. Writeup